Regular expressions are used in programming languages to match parts of strings. You create patterns to help you do that matching.
QuantifierDescription
| n+ | Matches any string that contains at least one n |
| n* | Matches any string that contains zero or more occurrences of n |
| n? | Matches any string that contains zero or one occurrences of n |
| n{X} | Matches any string that contains a sequence of X n's |
| n{X,Y} | Matches any string that contains a sequence of X to Y n's |
| n{X,} | Matches any string that contains a sequence of at least X n's |
| n$ | Matches any string with n at the end of it |
| ^n | Matches any string with n at the beginning of it |
| ?=n | Matches any string that is followed by a specific string n |
| ?!n | Matches any string that is not followed by a specific string n |
MetacharacterDescription
| . | Find a single character, except newline or line terminator |
| \w | Find a word character |
| \W | Find a non-word character |
| \d | Find a digit |
| \D | Find a non-digit character |
| \s | Find a whitespace character |
| \S | Find a non-whitespace character |
| \b | Find a match at the beginning/end of a word, beginning like this: \bHI, end like this: HI\b |
| \B | Find a match, but not at the beginning/end of a word |
| \0 | Find a NUL character |
| \n | Find a new line character |
| \f | Find a form feed character |
| \r | Find a carriage return character |
| \t | Find a tab character |
| \v | Find a vertical tab character |
| \xxx | Find the character specified by an octal number xxx |
| \xdd | Find the character specified by a hexadecimal number dd |
| \udddd | Find the Unicode character specified by a hexadecimal number dddd |
1. .test()
var str = "Hello world";
var testing = /world/;
testing.test(str); //outputs true
can add | for multiple search
let petString = "James has a pet cat.";
let petRegex = /dog|cat|bird|fish/; // Change this line
let result = petRegex.test(petString);
add i on the back to ignore upperlower case
let myString = "freeCodeCamp";
let fccRegex = /freecodecamp/i; // Change this line
let result = fccRegex.test(myString);
2. .match()
extracts the string
add g on the back for multiple results
To search or extract a pattern more than once, you can use the g flag.
let repeatRegex = /Repeat/g;
testStr.match(repeatRegex);
// Returns ["Repeat", "Repeat", "Repeat"]
The wildcard character . will match any one character.
[] Character classes allow you to define a group of characters you wish to match by placing them inside square ([ and ]) brackets.

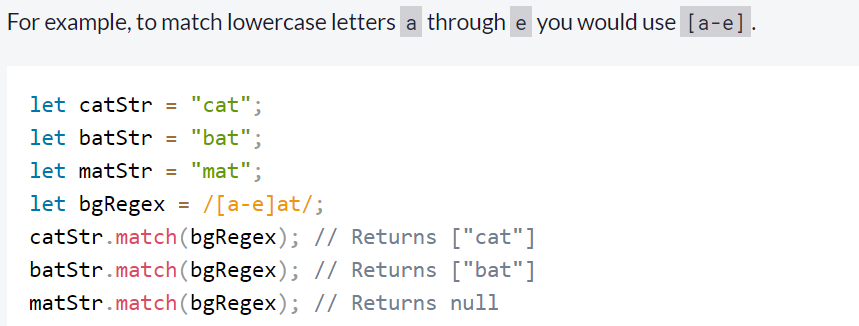
Inside a character set, you can define a range of characters to match using a hyphen character: -.
To create a negated character set, you place a caret character (^) after the opening bracket and before the characters you do not want to match.
For example, /[^aeiou]/gi matches all characters that are not a vowel. Note that characters like ., !, [, @, / and white space are matched - the negated vowel character set only excludes the vowel characters.
+ to look for a character one or more time
* to look for a character zero or more time
In an earlier challenge, you used the caret character (^) inside a character set to create a negated character set in the form [^thingsThatWillNotBeMatched]. Outside of a character set, the caret is used to search for patterns at the beginning of strings.
You can search the end of strings using the dollar sign character $ at the end of the regex.
The closest character class in JavaScript to match the alphabet is \w. This shortcut is equal to [A-Za-z0-9_]. This character class matches upper and lowercase letters plus numbers. Note, this character class also includes the underscore character (_).
\w = a-zA-Z0-9
\W = not \w
\d = 0-9
\D = not digit
problem 1:
1) Usernames can only use alpha-numeric characters.
2) The only numbers in the username have to be at the end. There can be zero or more of them at the end.
3) Username letters can be lowercase and uppercase.
4) Usernames have to be at least two characters long. A two-character username can only use alphabet letters as characters.
let username = "JackOfAllTrades";
let userCheck = /^[a-z]([0-9]{2,}|[a-z]+\d*)$/i; // Change this line
let result = userCheck.test(username);
- ^ - start of input
- [a-z] - first character is a letter
- [0-9]{2,0} - ends with two or more numbers
- | - or
- [a-z]+ - has one or more letters next
- \d* - and ends with zero or more numbers
- $ - end of input
- i - ignore case of input
------
to match only the string "hah" with the letter a appearing at least 3 times, your regex would be /ha{3,}h/.
t{3,6} = 3 to 6
t{3,} = 3 or more
t{3} = 3
? = zero or more
A positive lookahead will look to make sure the element in the search pattern is there, but won't actually match it. A positive lookahead is used as (?=...) where the ... is the required part that is not matched.
On the other hand, a negative lookahead will look to make sure the element in the search pattern is not there. A negative lookahead is used as (?!...) where the ... is the pattern that you do not want to be there. The rest of the pattern is returned if the negative lookahead part is not present.


remove white spaces
let regex = /^\s+|\s+$/g;
str.replace(regex, "");
'IT > ETC' 카테고리의 다른 글
| REGEX (0) | 2020.02.12 |
|---|---|
| FCM notification send (0) | 2020.02.11 |
| es6 (0) | 2020.02.10 |
| JSON APIs and Ajax (0) | 2020.02.10 |
| Basic Javascript (0) | 2020.02.08 |
