1. 클래스가 왜 필요한지 ? - 학생 정보를 관리한다고 했을때 새로운 학생이 추가할때는 배열을 사용해서 새로운 변수 선언 수고스러움과 지져분함을 최소화할 수 있다. - 다만 이렇게 배열로 관리를하면 배열이 나눠져 있고 데이터가 다양화될시 변경할 때 조심스럽게 작업해야한다. (ex. 인덱스 정확하게 맞추기) - 인덱스 기준으로 관리를해야하고 휴먼 에러가 날 가능성이 매우 높다. (컴퓨터가 봤을때는 문제 없지만 사람이 관리하기에는 좋은 코드가 아니다.) - 위와 같은 부분을 해결하기 위해서 클래스를 사용한다.
2. 클래스 - 클래스에 정의한 변수 -> 멤버 변수 or 필드 멤버 변수 : 특정 클래스에 소속된 멤버이기 때문에 이렇게 부른다 필드 : 데이터 항목을 가르키는 전통적인 용어. - 자바에서는 멤버 변수 == 필드 - 타입은 데이터의 종류/형태를 뜻하고, student이라는 타입을 만들기위해서 필요한건 설계도, 설계도가 클래스다. - 클래스는 설계도, 설계도 기반으로 실제 메모리에 만들어진 실체는 객체/인스터스라고 한다
Student student1 = new Student(); // 1. 객체 생성 Student student1 = x001; // 2. new Student()의 결과로 x001 참조값 반환 student1 = x001; // 3. 최종 결과
기타
- 클레스는 설계도 - 객체는 클래스의 실체 - 인스턴스는 특정 클래스로부터 생성된 객체 = 모든 인스턴스는 객체이지만 우리가 인스턴스라고 부르는 순간은 특정 클래스로부터 그 객체가 생성되었음을 강조하고 싶을때이다. ex. student1 객체는 Student 클래스의 인스턴스
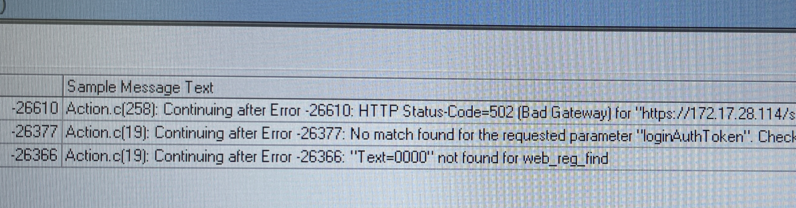
담당하고 있는 프로젝트에 고도화를 진행하면서 새로운 연동 서비스가 추가 되었다. 해당 서비스와 연동을 하면서 트래픽 증가가 예상이 되어서 로드러너를 통해 과부하 테스트를 진행을 했다. 로드러너 테스트를 진행하면서 동시다발적으로 에러들이 발생을 해서 관련 내용을 정리하고자 한다.
서버 구성도는 on-premise환경, 3tier 형식으로 구축되어있다. 추가로 테스트는 WEB1 -> WAS1 -> DB + 시뮬서버1 으로 과부하 테스트를 했다.
해결책은 정말 간단했다. CPU였다. HTTP 통신은 CPU를 사용한다. 해당 서버에 CPU 사용량이 100% 이상 넘어갈시 해당 서버에 요청이 들어와도 정상 처리를 못한다. 서버에 CPU에 증가량의 원인은 다양하지만 대표적인건 thread pool의 size그리고 로그 출력이다. 로그의 레벨만 제대로 설정하면 cpu의 사용량이 기본 60%에서 30%까지 떨어지는걸 눈으로 확인할 수 있다. (CPU확인 스크립트는 포스트 참고 = https://tonyzorz.tistory.com/139)
추가적으로 JVM의 힙설정 + 웹의 retry, timeout 시간을 늘리면 또한 처리가 안될시 방안이 될수 있다.